Tutorial 1: Using TimeseriesExtractor#
![]()
This module is designed to perform timeseries extraction, nuisance regression, and visualization. Additionally, it
generates the necessary dictionary structure required for CAP. If the BOLD images have not been preprocessed using
fMRIPrep (or a similar pipeline), the dictionary structure can be manually created.
The output in the Extracting Timeseries section is generated from a test run using GitHub Actions. This test uses a truncated version of the open dataset provided by Laumann & Poldrack [1] and was obtained from the OpenfMRI database, accession number ds000031.
Extracting Timeseries#
Download test dataset used for Github Actions from Github.
import os, subprocess, sys
demo_dir = "neurocaps_demo"
os.makedirs(demo_dir, exist_ok=True)
if sys.platform != "win32":
cmd = (
"cd neurocaps_demo && "
"git clone --depth 1 --filter=blob:none --sparse https://github.com/donishadsmith/neurocaps.git && "
"cd neurocaps && "
"git sparse-checkout set tests/data/dset &&"
"git submodule update --init --depth 1 -- tests/data"
)
os.system(cmd)
else:
repo_dir = os.path.join(demo_dir, "neurocaps")
# Enable git longpath
subprocess.run(
["git", "config", "--global", "core.longpaths", "true"],
check=True,
)
subprocess.run(
[
"git",
"clone",
"--depth",
"1",
"--filter=blob:none",
"--sparse",
"https://github.com/donishadsmith/neurocaps.git",
],
check=True,
cwd=demo_dir,
)
subprocess.run(
["git", "submodule", "update", "--init", "--depth", "1", "--", "tests/data"],
check=True,
cwd=repo_dir,
)
# Rename folder
os.makedirs("neurocaps_demo/data", exist_ok=True)
os.rename("neurocaps_demo/neurocaps/tests/data/dset", "neurocaps_demo/data/dset")
Note: when an asterisk (*) follows a name, all confounds that start with the preceding term will be automatically included. For example, placing an asterisk after cosine (cosine*) will utilize all parameters that begin with cosine.
from neurocaps.extraction import TimeseriesExtractor
confounds = ["cosine*", "a_comp_cor*", "rot*"]
parcel_approach = {"Schaefer": {"n_rois": 100, "yeo_networks": 7, "resolution_mm": 2}}
extractor = TimeseriesExtractor(
space="MNI152NLin2009cAsym",
parcel_approach=parcel_approach,
standardize=True,
use_confounds=True,
low_pass=0.15,
high_pass=None,
confound_names=confounds,
)
extractor.get_bold(
bids_dir="neurocaps_demo/data/dset",
session="002",
task="rest",
pipeline_name="fmriprep_1.0.0/fmriprep",
tr=1.2,
progress_bar=True, # Parameter available in versions >= 0.21.5
)
2025-07-03 18:02:15,929 neurocaps.extraction._internals.confounds [INFO] Confound regressors to be used if available: cosine*, a_comp_cor*, rot*.
2025-07-03 18:02:17,442 neurocaps.extraction.timeseries_extractor [INFO] BIDS Layout: ...books\neurocaps_demo\data\dset | Subjects: 1 | Sessions: 1 | Runs: 1
2025-07-03 18:02:17,499 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 01 | SESSION: 002 | TASK: rest | RUN: 001] Preparing for Timeseries Extraction using [FILE: sub-01_ses-002_task-rest_run-001_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz].
2025-07-03 18:02:17,516 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 01 | SESSION: 002 | TASK: rest | RUN: 001] The following confounds will be used for nuisance regression: cosine_00, cosine_01, cosine_02, cosine_03, cosine_04, cosine_05, cosine_06, a_comp_cor_00, a_comp_cor_01, a_comp_cor_02, a_comp_cor_03, a_comp_cor_04, a_comp_cor_05, rot_x, rot_y, rot_z.
Processing Subjects: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:05<00:00, 5.73s/it]
print can be used to return a string representation of the TimeseriesExtractor class.
print(extractor)
Current Object State:
===========================================================
Preprocessed BOLD Template Space : MNI152NLin2009cAsym
Parcellation Approach : Schaefer
Signal Clean Parameters : {'masker_init': {'detrend': False, 'low_pass': 0.15, 'high_pass': None, 'smoothing_fwhm': None}, 'standardize': True, 'use_confounds': True, 'confound_names': ['cosine*', 'a_comp_cor*', 'rot*'], 'n_acompcor_separate': None, 'dummy_scans': None, 'fd_threshold': 0.35, 'dtype': None}
Task Information : {'task': 'rest', 'session': '002', 'runs': None, 'condition': None, 'condition_tr_shift': 0, 'tr': 1.2, 'slice_time_ref': 0.0}
Number of Subjects : 1
CPU Cores Used for Timeseries Extraction (Multiprocessing) : None
Subject Timeseries Byte Size : 15784 bytes
The extracted timeseries is stored as a nested dictionary and can be accessed using the subject_timeseries
property. The TimeseriesExtractor class has several
properties.
Some properties can also be used as setters.
print(extractor.subject_timeseries)
{'01': {'run-001': array([[ 1.2033961 , -1.2330143 , -1.2266738 , ..., 0.79417294,
0.03897883, -1.2275234 ],
[-0.41716266, 0.18100384, 0.17953618, ..., -0.7285049 ,
0.46337456, 0.232506 ],
[-0.6353623 , 0.52065367, 0.51416904, ..., -0.6392374 ,
0.30418062, 0.5296185 ],
...,
[-0.00439697, -0.33513063, -0.344346 , ..., -1.7402033 ,
0.6538972 , -0.48667648],
[-0.21270348, 0.5142317 , 0.5091558 , ..., 0.5407353 ,
-0.7391407 , 0.4986693 ],
[-0.13190913, 0.53207046, 0.53672856, ..., 1.6365708 ,
-0.83822703, 0.65070736]], shape=(39, 100), dtype=float32)}}
Reporting Quality Control Metrics#
Note: Only censored frames with valid data on both sides are interpolated, while censored frames at the edge of the timeseries (including frames that border censored edges) are always scrubbed and counted in “Frames_Scrubbed”. Additionally, scipy’s Cubic Spline is used to only interpolate censored frames.
extractor.report_qc(output_dir=demo_dir, filename="qc.csv", return_df=True)
Subject_ID |
Run |
Mean_FD |
Std_FD |
Frames_Scrubbed |
Frames_Interpolated |
Mean_High_Motion_Length |
Std_High_Motion_Length |
N_Dummy_Scans |
|---|---|---|---|---|---|---|---|---|
01 |
run-001 |
0.10531541574999999 |
0.10997670447085037 |
1 |
0 |
1.0 |
0.0 |
NaN |
Saving Timeseries#
extractor.timeseries_to_pickle(output_dir=demo_dir, filename="rest_Schaefer.pkl")
Visualizing Timeseries#
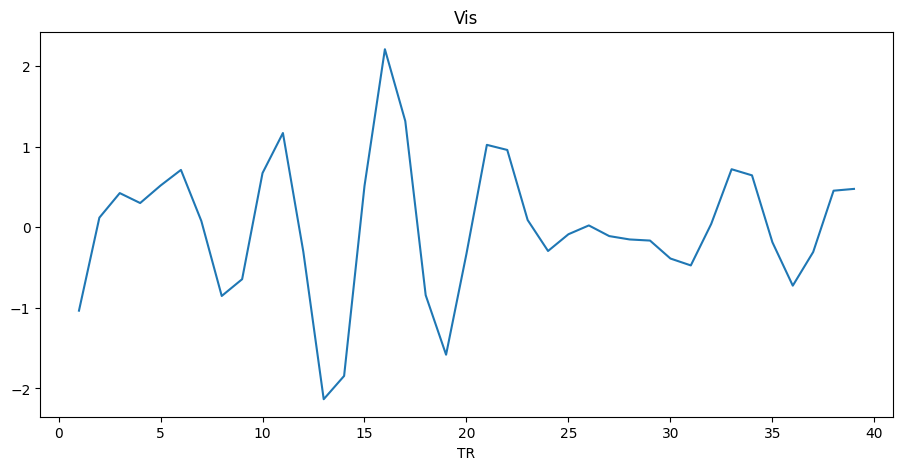
# Visualizing a region
extractor.visualize_bold(subj_id="01", run="001", region="Vis")
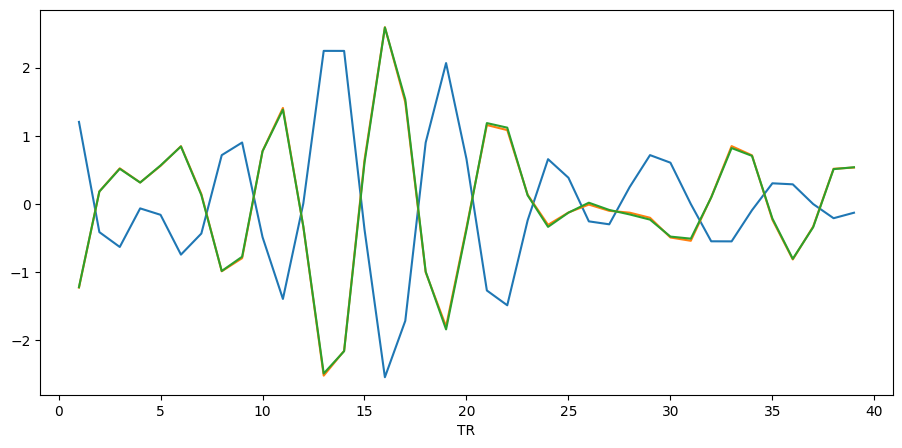
# Visualizing a several nodes
extractor.visualize_bold(subj_id="01", run="001", roi_indx=[0, 1, 2])
extractor.visualize_bold(subj_id="01", run="001", roi_indx=["LH_Vis_1", "LH_Vis_2", "LH_Vis_3"])