Tutorial 1: Preparing BOLD Data for Co-Activations Patterns (CAPs) Analysis#
![]()
![]()
TimeseriesExtractor performs timeseries extraction, nuisance regression, and visualization. Additionally, it generates the necessary dictionary structure required for CAP. If the BOLD images have not been preprocessed using fMRIPrep (or a similar pipeline), the dictionary structure can be manually created.
[1]:
# Download packages
try:
import neurocaps
except:
!pip install neurocaps[windows,demo]
Simulate Dataset#
Creating a simulated dataset for tutorial purposes.
[2]:
import os
import numpy as np
from neurocaps.utils import simulate_bids_dataset
np.random.seed(0)
# Create simulated BIDS directory with fMRIPrep derivatives
out_dir = os.path.join(os.getcwd(), "neurocaps_demo")
bids_root = simulate_bids_dataset(
n_subs=3, n_runs=1, n_volumes=100, task_name="rest", output_dir=out_dir
)
2025-07-21 23:58:22,909 neurocaps.utils._io [WARNING] Creating the following non-existent path: c:\Users\donis\Github\neurocaps\docs\tutorials\neurocaps_demo\derivatives\fmriprep.
Extracting Timeseries#
Note: Adding an asterisk to the end of a confound name collects all confounds starting with the word preceeding the asterisk.
[11]:
from neurocaps.extraction import TimeseriesExtractor
confounds = ["cosine*", "a_comp_cor*", "rot*"]
parcel_approach = {"Schaefer": {"n_rois": 100, "yeo_networks": 7, "resolution_mm": 2}}
extractor = TimeseriesExtractor(
space="MNI152NLin2009cAsym",
parcel_approach=parcel_approach,
standardize=True,
use_confounds=True,
low_pass=0.15,
high_pass=None,
confound_names=confounds,
fd_threshold=0.90,
)
2025-07-22 00:00:20,323 neurocaps.extraction._internals.confounds [INFO] Confound regressors to be used if available: cosine*, a_comp_cor*, rot*.
[4]:
# Extract bold data
extractor.get_bold(
bids_dir=bids_root,
task="rest",
tr=1.2,
n_cores=1,
progress_bar=False,
)
2025-07-21 23:59:48,329 neurocaps.extraction.timeseries_extractor [INFO] BIDS Layout: ...\docs\tutorials\neurocaps_demo | Subjects: 0 | Sessions: 0 | Runs: 0
2025-07-21 23:59:48,400 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 0 | SESSION: None | TASK: rest | RUN: 0] Preparing for Timeseries Extraction using [FILE: sub-0_task-rest_run-0_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz].
2025-07-21 23:59:48,413 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 0 | SESSION: None | TASK: rest | RUN: 0] The following confounds will be used for nuisance regression: cosine_00, cosine_01, cosine_02, cosine_03, cosine_04, cosine_05, cosine_06, a_comp_cor_00, a_comp_cor_01, a_comp_cor_02, a_comp_cor_03, a_comp_cor_04, a_comp_cor_05, rot_x, rot_y, rot_z.
2025-07-21 23:59:58,899 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 1 | SESSION: None | TASK: rest | RUN: 0] Preparing for Timeseries Extraction using [FILE: sub-1_task-rest_run-0_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz].
2025-07-21 23:59:58,913 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 1 | SESSION: None | TASK: rest | RUN: 0] The following confounds will be used for nuisance regression: cosine_00, cosine_01, cosine_02, cosine_03, cosine_04, cosine_05, cosine_06, a_comp_cor_00, a_comp_cor_01, a_comp_cor_02, a_comp_cor_03, a_comp_cor_04, a_comp_cor_05, rot_x, rot_y, rot_z.
2025-07-22 00:00:09,810 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 2 | SESSION: None | TASK: rest | RUN: 0] Preparing for Timeseries Extraction using [FILE: sub-2_task-rest_run-0_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz].
2025-07-22 00:00:09,817 neurocaps.extraction._internals.postprocess [INFO] [SUBJECT: 2 | SESSION: None | TASK: rest | RUN: 0] The following confounds will be used for nuisance regression: cosine_00, cosine_01, cosine_02, cosine_03, cosine_04, cosine_05, cosine_06, a_comp_cor_00, a_comp_cor_01, a_comp_cor_02, a_comp_cor_03, a_comp_cor_04, a_comp_cor_05, rot_x, rot_y, rot_z.
[4]:
<neurocaps.extraction.timeseries_extractor.TimeseriesExtractor at 0x1df40e37b50>
print can be used to return a string representation of the TimeseriesExtractor class.
[5]:
print(extractor)
Current Object State:
===========================================================
Preprocessed BOLD Template Space : MNI152NLin2009cAsym
Parcellation Approach : Schaefer
Signal Cleaning Parameters : {'masker_init': {'detrend': False, 'low_pass': 0.15, 'high_pass': None, 'smoothing_fwhm': None}, 'standardize': True, 'use_confounds': True, 'confound_names': ['cosine*', 'a_comp_cor*', 'rot*'], 'n_acompcor_separate': None, 'dummy_scans': None, 'fd_threshold': 0.9, 'dtype': None}
Task Information : {'task': 'rest', 'session': None, 'runs': None, 'condition': None, 'condition_tr_shift': 0, 'tr': 1.2, 'slice_time_ref': 0.0}
Number of Subjects : 3
CPU Cores Used for Timeseries Extraction (Multiprocessing) : 1
Subject Timeseries Byte Size : 212984 bytes
The extracted timeseries is stored as a nested dictionary and can be accessed using the subject_timeseries property. The TimeseriesExtractor class has several properties Some properties can also be used as setters.
[6]:
print(extractor.subject_timeseries)
{'0': {'run-0': array([[ 0.09402057, 0.1449876 , 2.35627508, ..., -1.63226598,
-2.73053506, 0.21236354],
[ 0.22086913, -0.15716305, -0.32993113, ..., -0.1080912 ,
0.08950075, -1.05933416],
[ 0.47791352, -0.51340932, -2.0038014 , ..., 0.80576622,
1.47763991, -1.80146365],
...,
[ 1.33354083, -0.52305732, -0.62114048, ..., -1.26069969,
1.41603063, 1.22699535],
[ 0.76237919, -0.57977302, -0.01786115, ..., -0.63702198,
0.86069391, 1.96176128],
[-0.61688648, -0.5266736 , 1.58365278, ..., -0.53117929,
-1.87386837, 2.38755092]], shape=(91, 100))}, '1': {'run-0': array([[-1.42461187, 1.32228549, -1.0190435 , ..., -2.69195092,
4.42061077, -2.68506046],
[-0.30923692, 0.51083401, -1.78292672, ..., -1.74358399,
2.342345 , -0.69399608],
[-0.15699436, 0.10718122, -2.15780216, ..., -1.22464306,
0.63464183, 0.3217322 ],
...,
[ 1.42470073, 1.16019942, 0.87668332, ..., 0.79620718,
1.57581104, -1.28037996],
[ 0.70817175, -1.75687412, -0.67453177, ..., -0.3927773 ,
-1.88153021, -1.10110024],
[-1.03564988, 2.30536487, 1.05963724, ..., -0.13935338,
0.50765321, -1.76385674]], shape=(83, 100))}, '2': {'run-0': array([[ 2.06135057, 0.47938026, -0.96410173, ..., 0.33430144,
-2.88452688, 0.4820153 ],
[-0.52985325, 2.10179644, 0.32204473, ..., 0.12825758,
-0.45462174, 0.55922981],
[-1.46780889, 2.18079527, 0.63344499, ..., 0.00993256,
0.75288327, 0.30140228],
...,
[-1.29226198, -0.27876479, 0.67621844, ..., -1.92293297,
1.47214869, -0.42091987],
[-1.46182617, -1.07474042, 1.39474068, ..., -2.29016531,
2.23378222, -0.42599184],
[ 0.5882894 , -0.51961812, 1.03746322, ..., -0.1906019 ,
1.20551913, -1.57312055]], shape=(92, 100))}}
Reporting Quality Control Metrics#
Checking statistics on framewise displacement and dummy volumes using the self.report_qc method. Only censored frames with valid data on both sides are interpolated, while censored frames at the edge of the timeseries (including frames that border censored edges) are always scrubbed and counted in “Frames_Scrubbed”. In the data, the last frame is the only one with an FD > 0.35. Additionally, scipy’s Cubic
Spline is used to only interpolate censored frames.
[7]:
extractor.report_qc(output_dir=bids_root, filename="qc.csv", return_df=True)
[7]:
| Subject_ID | Run | Mean_FD | Std_FD | Frames_Scrubbed | Frames_Interpolated | Mean_High_Motion_Length | Std_High_Motion_Length | N_Dummy_Scans | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | run-0 | 0.516349 | 0.289657 | 9 | 0 | 1.125000 | 0.330719 | NaN |
| 1 | 1 | run-0 | 0.526343 | 0.297550 | 17 | 0 | 1.133333 | 0.339935 | NaN |
| 2 | 2 | run-0 | 0.518041 | 0.273964 | 8 | 0 | 1.000000 | 0.000000 | NaN |
Saving Timeseries#
[8]:
extractor.timeseries_to_pickle(output_dir=bids_root, filename="rest_Schaefer.pkl")
[8]:
<neurocaps.extraction.timeseries_extractor.TimeseriesExtractor at 0x1df40e37b50>
Visualizing Timeseries#
[9]:
# Visualizing a region
from neurocaps.utils import PlotDefaults
plot_kwargs = PlotDefaults.visualize_bold()
plot_kwargs["figsize"] = (8, 6)
extractor.visualize_bold(subj_id="1", run="0", region="Vis", **plot_kwargs)
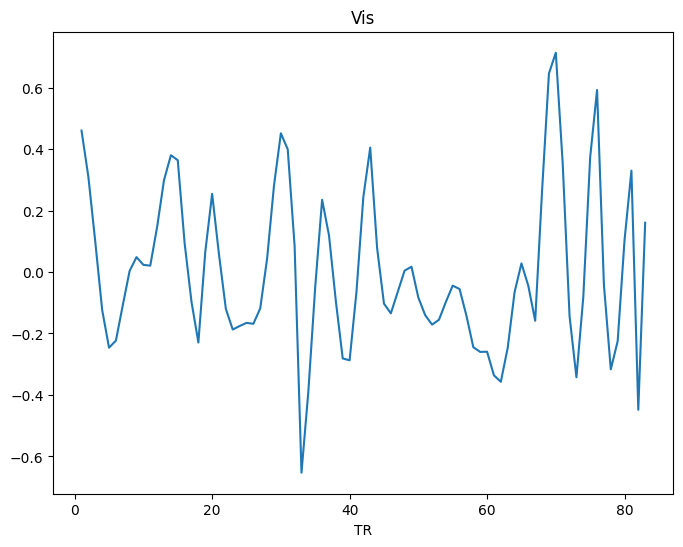
[9]:
<neurocaps.extraction.timeseries_extractor.TimeseriesExtractor at 0x1df40e37b50>
[10]:
# Visualizing a several nodes
extractor.visualize_bold(subj_id="1", run="0", roi_indx=[0, 1, 2], **plot_kwargs)
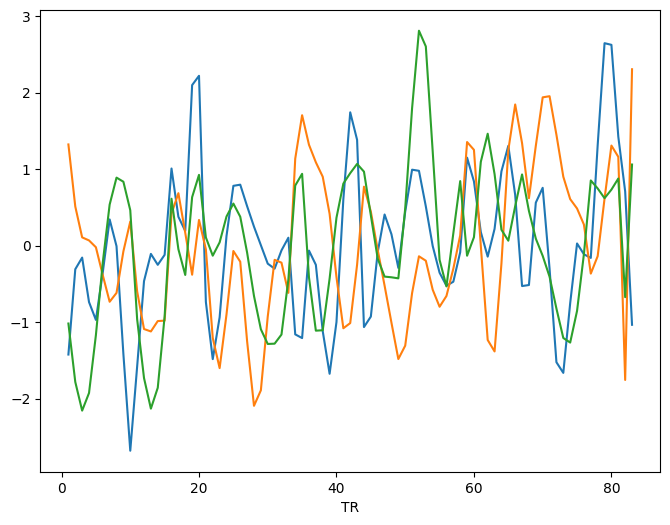
[10]:
<neurocaps.extraction.timeseries_extractor.TimeseriesExtractor at 0x1df40e37b50>